SELECTED PUBLICATIONS
Full paper list can be found at DBLP and Google Scholar.
JOURNAL PAPERS
Video Pivoting Unsupervised Multi-modal Machine Translation

- We propose a novel method to leverage visual contents to synthesize additional pseudo-pivoting for unsupervised multimodal machine translation.
Mingjie Li, Poyao Huang, Xiaojun Chang*, Junjie Hu, Yi Yang and Alex Hauptmann
IEEE Trans. Pattern Anal. Mach. Intell. 45(3):3918-3932 (2023)
pdf
When Object Detection Meets Knowledge Distillation:A Survey
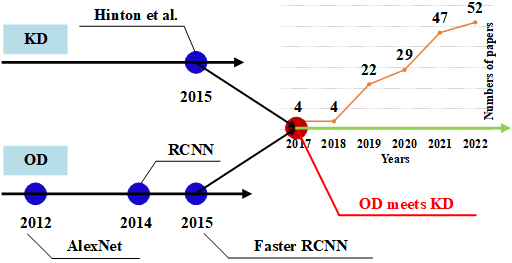
- This paper provides a comprehensive survey of recent research on using knowledge distillation (KD) techniques to improve the efficiency and accuracy of object detection models.
Zhihui Li, Pengfei Xu, Xiaojun Chang, Luyao Yang, Yuanyuan Zhang, Lina Yao and Xiaojiang Chen
IEEE Trans. Pattern Anal. Mach. Intell. 45(8):10555-10579 (2023)
pdf
Attribute-guided Collaborative Learning for Partial Person Re-identification
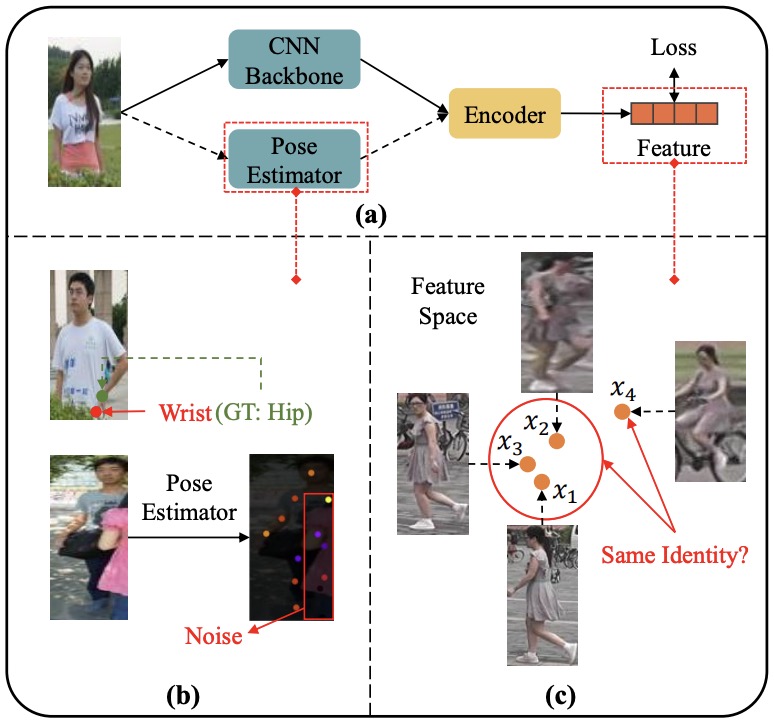
- We present a novel attribute-guided collaborative learning scheme for partial person ReID. It jointly integrates noisy keypoint restraint, structured multi-modal representation aggregation, and robust pedestrian representation learning into a unified framework.
Haoyu Zhang, Meng Liu, Yuhong Li, Ming Yan, Zan Gao, Xiaojun Chang, Liqiang Nie
IEEE Trans. Pattern Anal. Mach. Intell. 45(12):14144-14160 (2023)
pdf
Simple Primitives with Feasibility- and Contextuality-Dependence for Open-World Compositional Zero-shot Learning
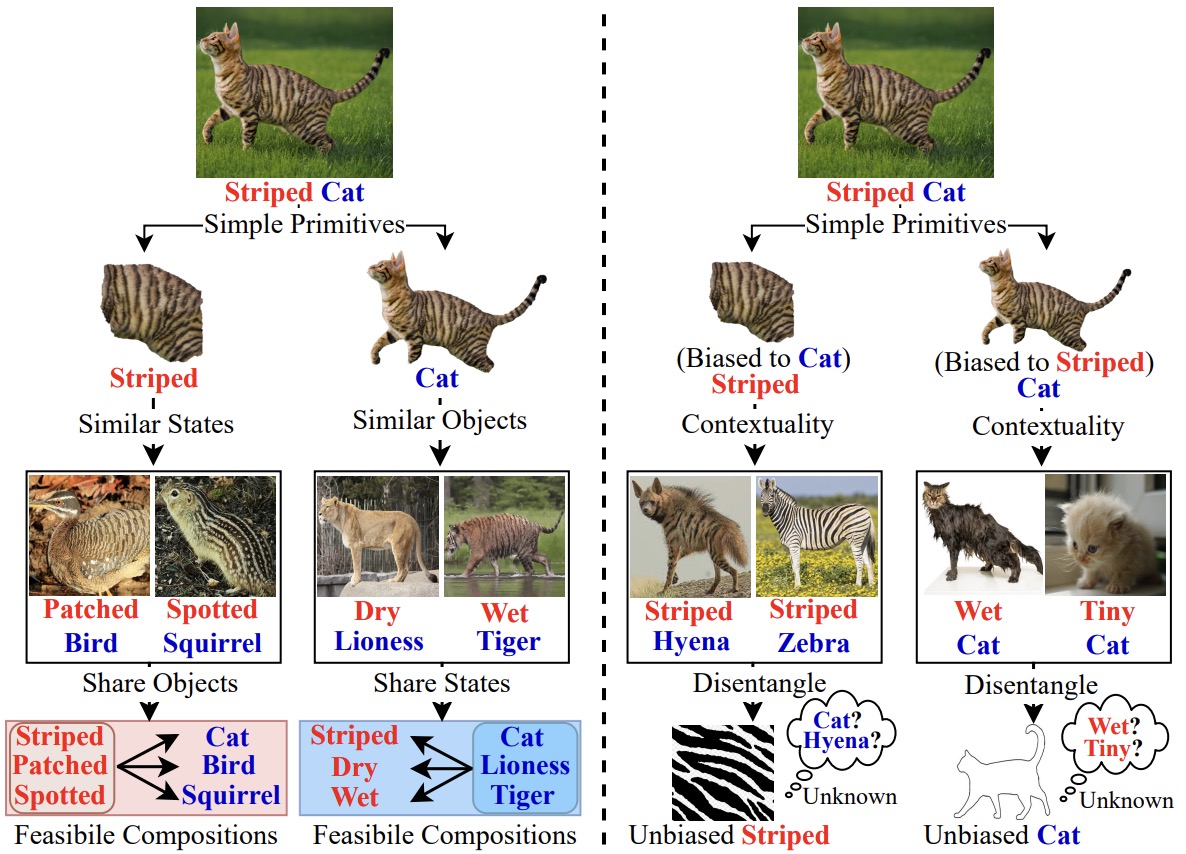
- we model the dependence of compositions via feasibility and contextuality
Zhe Liu, Yun Li, Lina Yao, Xiaojun Chang, Wei Fang, Xiaojun Wu, Abdulmotaleb El Saddik
IEEE Trans. Pattern Anal. Mach. Intell. (T-PAMI), 2023
pdf
DNA Family:Boosting Weight-Sharing NAS with Block-Wise Supervisions
- We use a generalization boundedness tool to attribute weight-sharing NAS’s ineffectiveness to unreliable architecture ratings caused by large search space.
Guangrun Wang, Changlin Li, Liuchun Yuan, Jiefeng Peng, Xiaoyu Xian, Xiaodan Liang, Xiaojun Chang and Liang Lin
IEEE Trans. Pattern Anal. Mach. Intell. (T-PAMI), 2023
pdf
TN-ZSTAD:Transferable Network for Zero-Shot Temporal Activity Detection
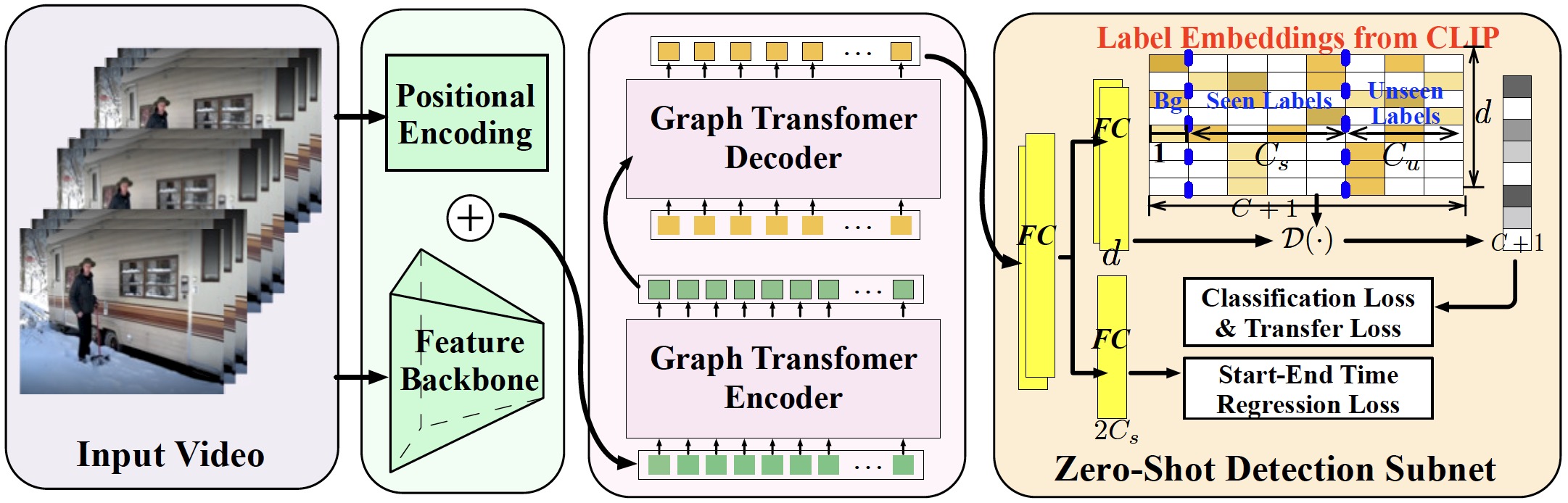
- We propose a novel framework TN-ZSTAD for zero-shot temporal activity detection, which combines a graph activity transformer (AGT) and a zeroshot detection subnet (ZSDN) together to infer a set of unseen activity instances for a input video directly.
Lingling Zhang, Xiaojun Chang*, Jun Liu, Minnan Luo, Zhihui Li, Lina Yao, and Alex Hauptmann
IEEE Trans. Pattern Anal. Mach. Intell. 45(3):3848-3861 (2023)
pdf
A Comprehensive Survey of Scene Graphs:Generation and Application
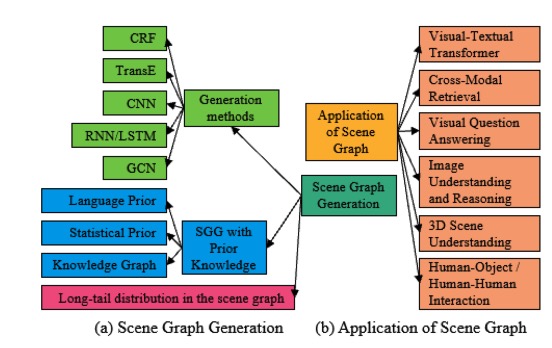
- This survey conducts a comprehensive investigation of the current scene graph research
Xiaojun Chang, Pengzhen Ren, Pengfei Xu, Zhihui Li, Xiaojiang Chen and Alex Hauptmann
IEEE Trans. Pattern Anal. Mach. Intell. 45(1):1-26 (2023)
pdf
ZeroNAS:Differentiable Generative Adversarial Networks Search for Zero-Shot Learning
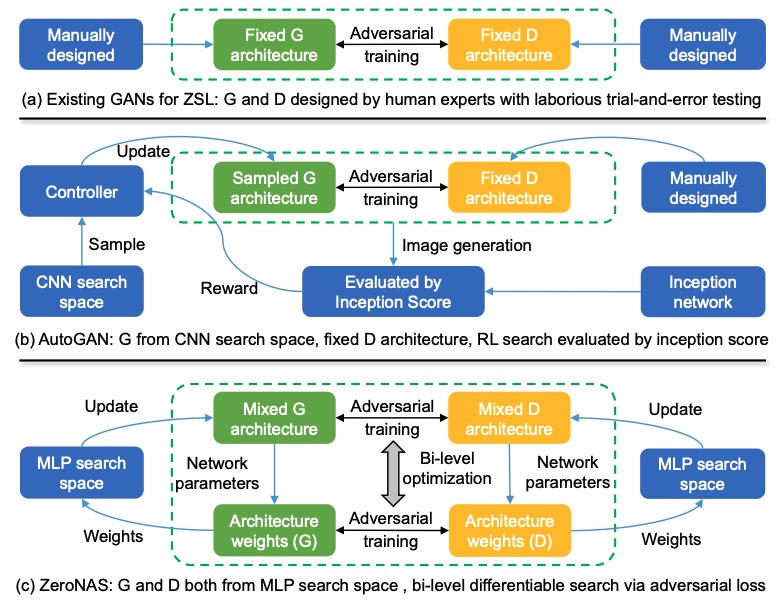
- Considering the varieties in datasets and tasks, we make the first attempt to bring NAS techniques into the realm of ZSL, and thus propose ZeroNAS to formulate the GAN architecture design for ZSL as a NAS problem.
Caixia Yan, Xiaojun Chang*, Zhihui Li, Weili Guan, Zongyuan Ge, Lei Zhu and Qinghua Zheng
IEEE Trans. Pattern Anal. Mach. Intell. 44(12):9733-9740 (2022)
pdf
|
code
DS-Net++:Dynamic Weight Slicing for Efficient Inference in CNNs and Vision Transformers
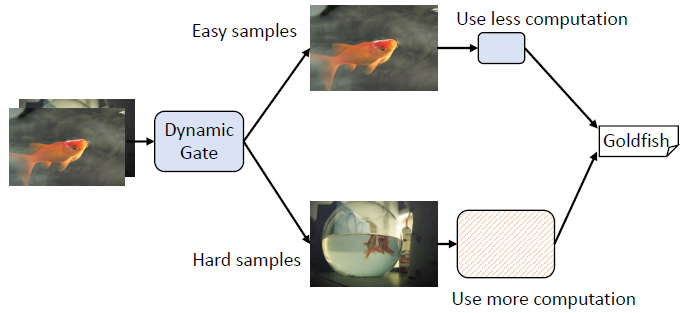
- propose dynamic weight slicing scheme, achieving good hardware-efficiency by predictively slicing network parameters at test time with respect to different inputs.
Changlin Li, Guangrun Wang, Xiaodan Liang, Zhihui Li, and Xiaojun Chang*
IEEE Trans. Pattern Anal. Mach. Intell. 45(4):4430-4446 (2023)
pdf
Semantics-Guided Contrastive Network for Zero-Shot Object Detection
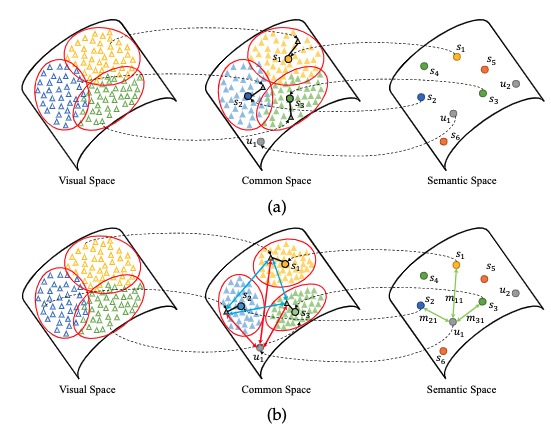
- We develop a novel semantics-guided contrastive net- work for ZSD, underpinned by a new mapping- contrastive strategy superior to the conventional mapping-transfer strategy. To the best of our knowl- edge, this is the first work that applies contrastive learning mechanism for ZSD.
Caixia Yan, Xiaojun Chang*, Minnan Luo, Huan Liu, Xiaoqin Zhang*, and Qinghua Zheng
IEEE Trans. Pattern Anal. Mach. Intell. (T-PAMI), DOI:10.1109/TPAMI.2021.3140070, 2021
pdf
One-Shot Neural Architecture Search:Maximising Diversity to Overcome Catastrophic Forgetting
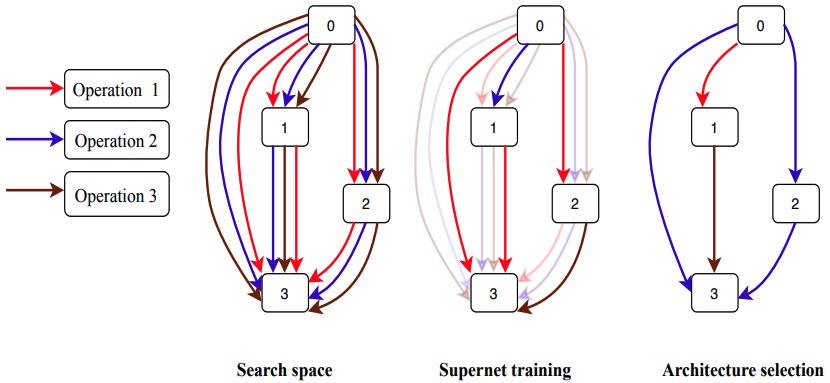
- To improve transferability, we further devised a variant of NSAS, called NSAS-C, which searches for deeper architectures in the convolutional cell search.
Miao Zhang, Huiqi Li, Shirui Pan, Xiaojun Chang, Chuan Zhou, Zongyuan Ge, and Steven Su
IEEE Trans. Pattern Anal. Mach. Intell. (T-PAMI), 2020
pdf
|
code
Semantic Pooling for Complex Event Analysis in Untrimmed Videos
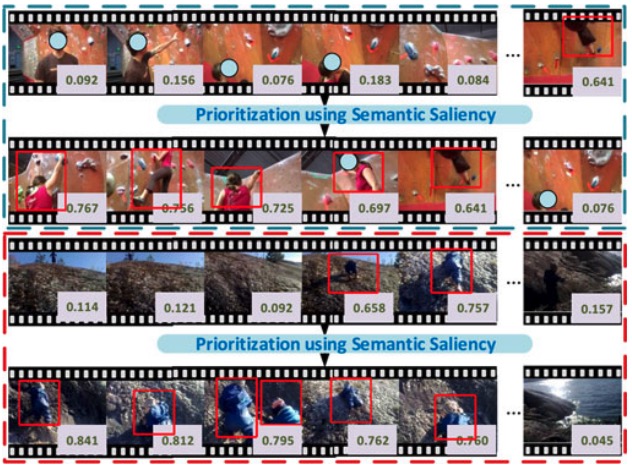
- design the informed nearly-isotonic SVM classifier (NI-SVM) that is able to exploit the carefully constructed ordering information
Xiaojun Chang, Yaoliang Yu, Yi Yang, Eric P. Xing
IEEE Trans. Pattern Anal. Mach. Intell. (T-PAMI) 39(8) 1617-1632 (2017)
pdf
|
code
A Comprehensive Survey of Neural Architecture Search:Challenges and Solutions
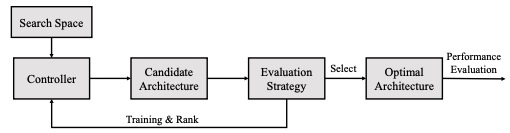
- we provide a new perspective, beginning with an overview of the characteristics of the earliest NAS algorithms, summarizing the problems in these early NAS algorithms, and then providing solutions for subsequent related research work
Pengzhen Ren, Yun Xiao, Xiaojun Chang, Po-Yao Huang, Zhihui Li, Xiaojiang Chen and Xin Wang
Accepted by ACM Computing Surveys, 2021
pdf
Multi-Class Active Learning by Uncertainty Sampling with Diversity Maximization
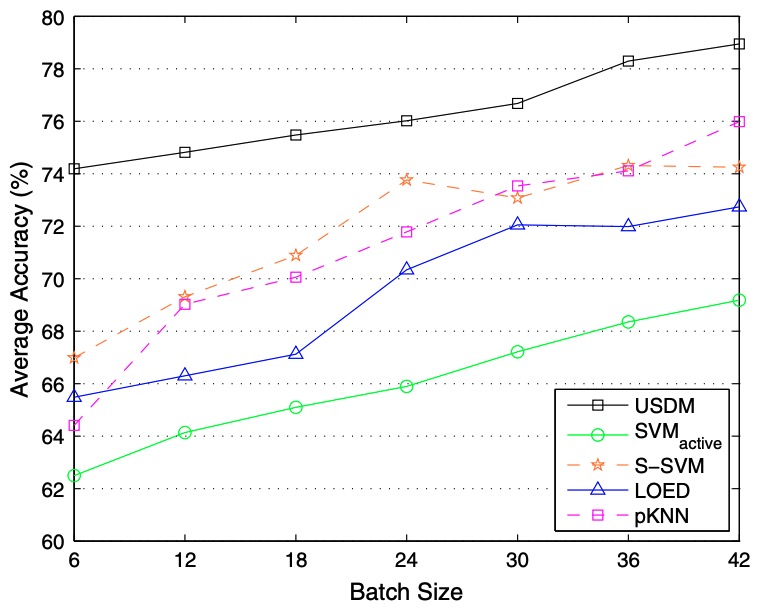
- propose a semi-supervised batch mode multi-class active learning algorithm for visual concept recognition
Yi Yang, Zhigang Ma, Feiping Nie, Xiaojun Chang, Alexander G. Hauptmann
International Journal of Computer Vision (IJCV) 113(2) 113-127 (2015)
pdf
Semantics Preserving Graph Propagation for Zero-Shot Object Detection
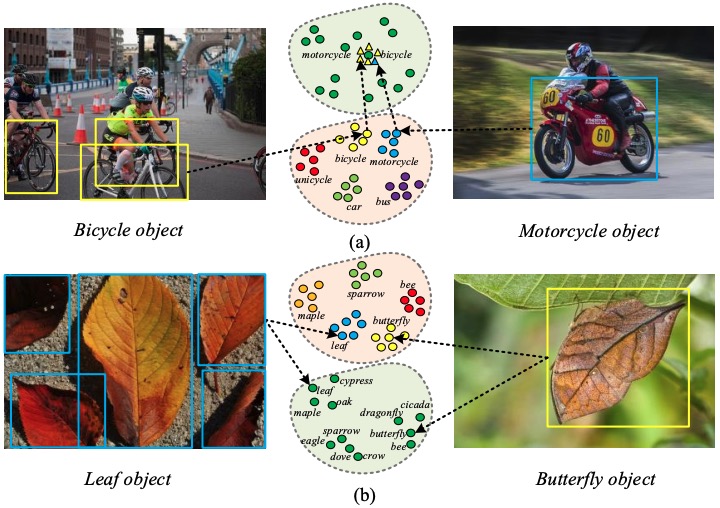
- propose a semantics preserving graph propagation model based on GCN for the challenging ZSD task, which leverages both the semantic description and structural knowledge in prior category graphs to facilitate the semantic coherency of region graph.
Caixia Yan, Qinghua Zheng, Xiaojun Chang, Minnan Luo, ChungHsing Yeh and Alexander G. Hauptmann
IEEE Transactions on Image Processing 29:8163-8176 (2020)
pdf
Self-supervised Deep Correlation Tracking
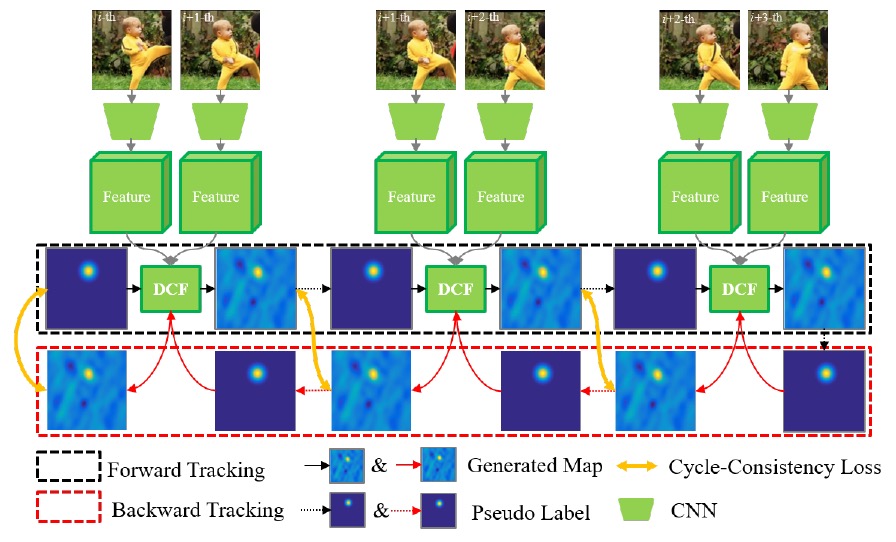
- formulate a multi-cycle consistency loss based selfsupervised learning manner to pre-training the deep feature extraction network, which can take advantage of extensive unlabeled video samples rather than limited manually annotated samples
Di Yuan, Xiaojun Chang, Po-Yao Huang, Qiao Liu, and Zhenyu He
IEEE Transactions on Image Processing 30:976-985 (2021)
pdf
CONFERENCE PAPERS
Cross-modal Clinical Graph Transformer For Ophthalmic Report Generation
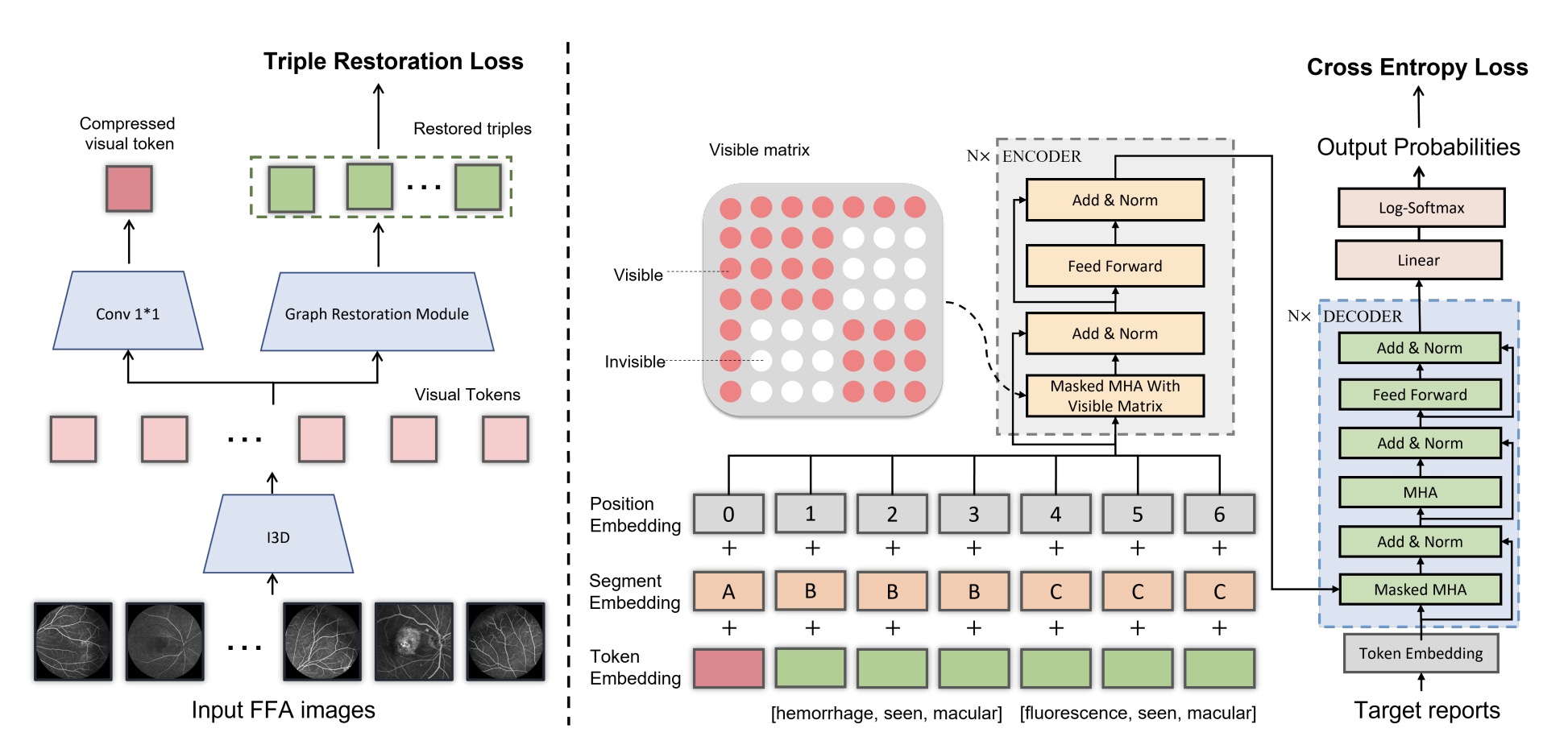
- we present an effective cross-modal clinical graph transformer for ophthalmic report generation
M. Li, W. Cai, K. Verspoor, S. Pan, X. Liang and X. Chang*
CVPR 2022
pdf
Beyond Fixation:Dynamic Window Visual Transformer
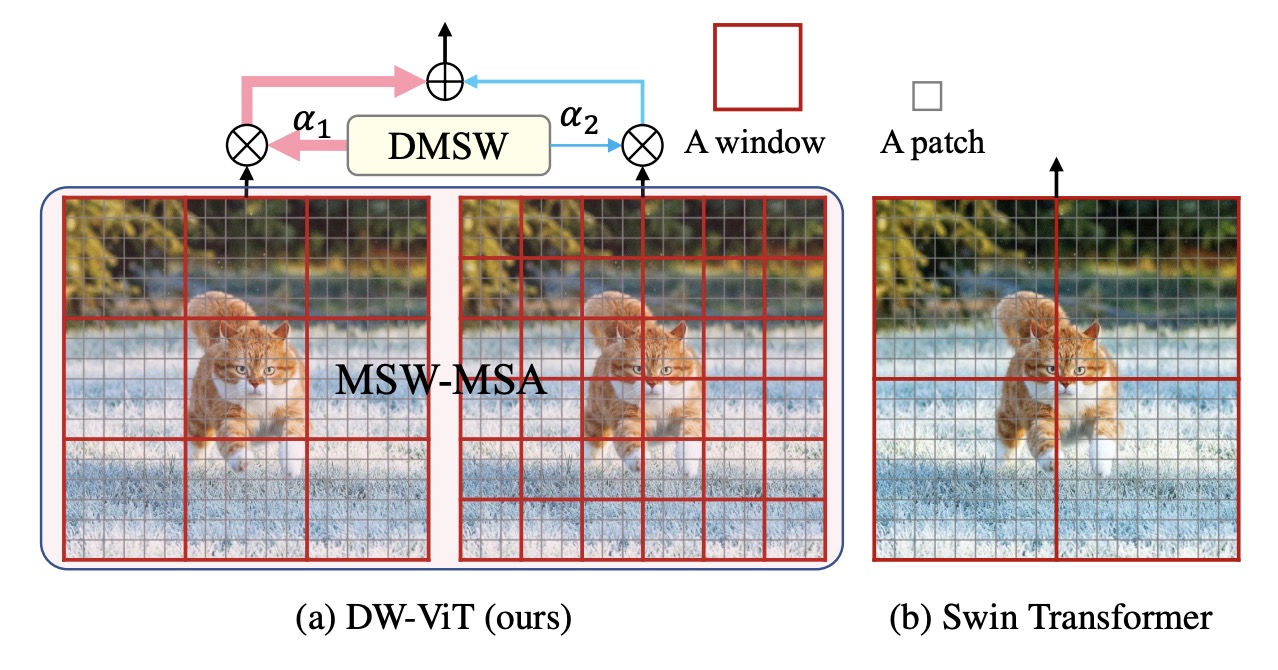
- propose a novel plug-and-play module with a dynamic multi-scale window for multi-head selfattention in transformer
P. Ren, C. Li, G. Wang, Y. Xiao, Q. Du, X. Liang, and X. Chang
CVPR 2022
pdf
Self-Supervised Global-Local Structure Modeling for Point Cloud Domain Adaptation with Reliable Voted Pseudo Labels
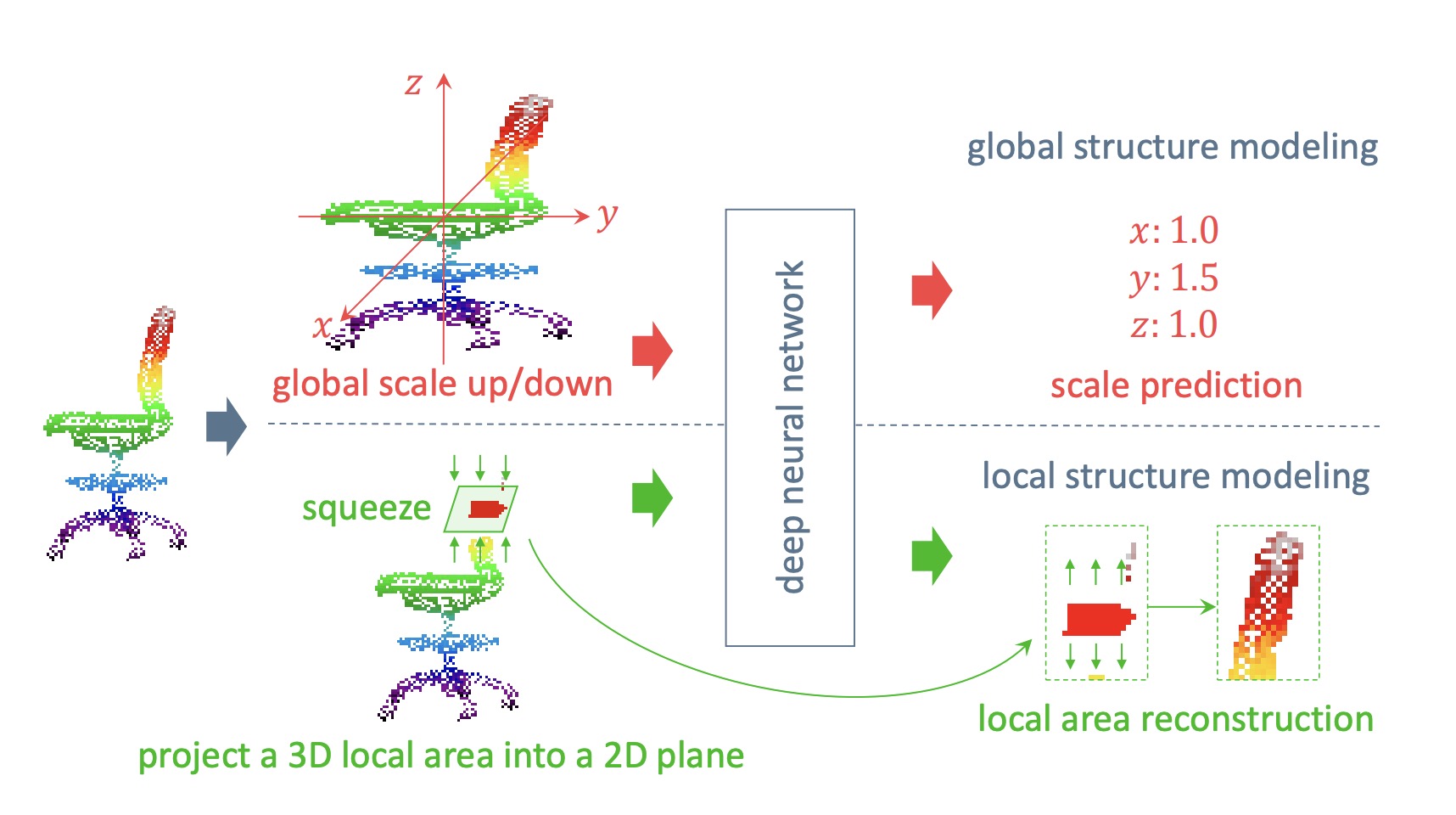
- propose a global scaling-up-down prediction method and a local 3D-2D-3D projectionreconstruction method for point cloud domain adaptation
H. Fan, X. Chang, W. Zhang, Y. Cheng, Y. Sun, and M. Kankanhalli
CVPR 2022
pdf
Automated Progressive Learning for Efficient Training of Vision Transformers
- develop a strong manual baseline for progressive learning of ViTs, by introducing MoGrow, a momentum growth strategy to bridge the gap brought by model growing
C. Li, B. Zhuang, G. Wang, X. Liang, X. Chang, and Y. Yang
CVPR 2022
pdf
BaLeNAS:Differentiable Architecture Search via Bayesian Learning Rule

- this paper formulates the neural architecture search as a distribution learning problem through relaxing the architecture weights into Gaussian distributions
M. Zhang, S. Pan, X. Chang, S. Su, J. Hu, R. Haffari, and B. Yang
CVPR 2022
pdf
Dual-AI:Dual-path Actor Interaction Learning for Group Activity Recognition
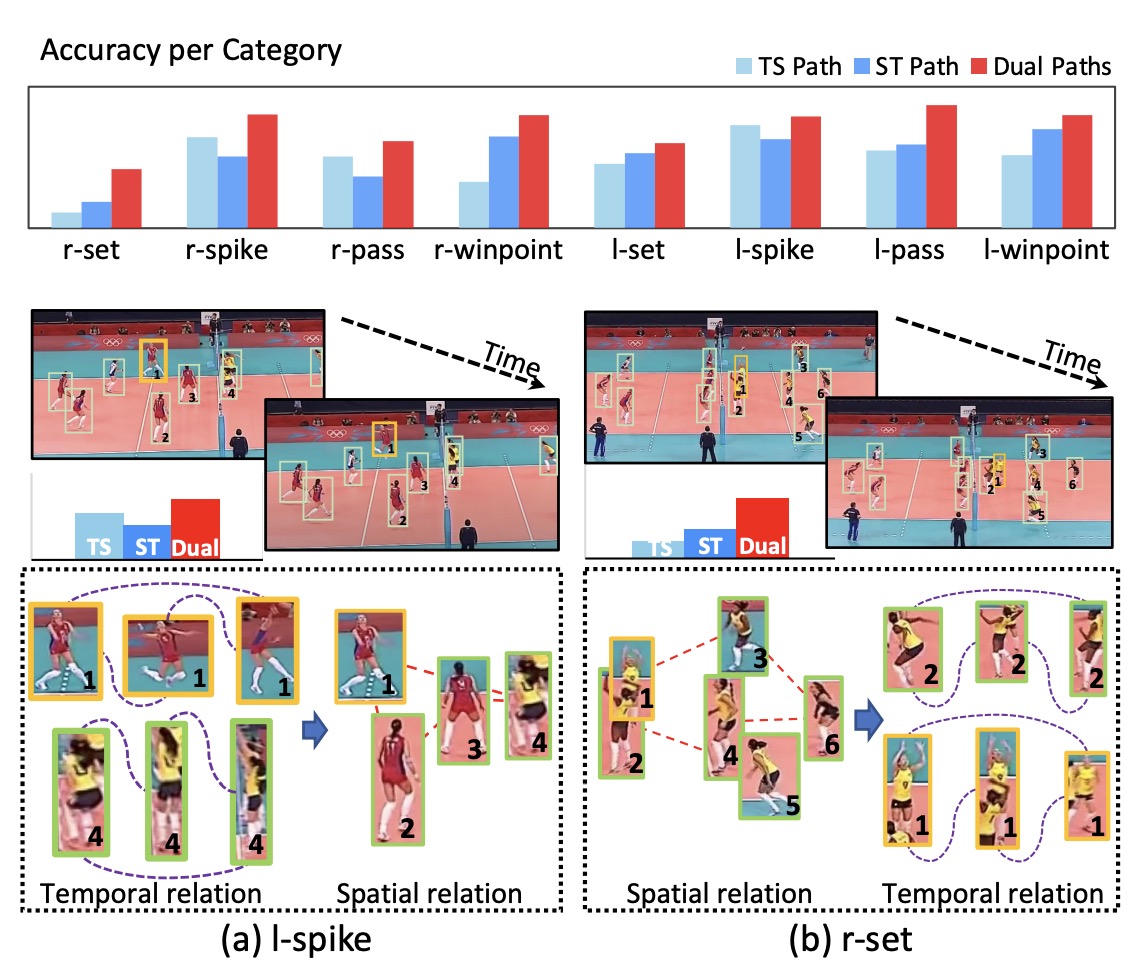
- propose a distinct Dual-path Actor Interaction (DualAI) framework, which flexibly arranges spatial and temporal transformers in two complementary orders, enhancing actor relations by integrating merits from different spatiotemporal paths
M. Han, D. J. Zhang, Y. Wang, R. Yan, L. Yao, X. Chang*, and Y. Qiao
CVPR 2022
pdf
Knowledge Distillation via the Target-aware Transformer
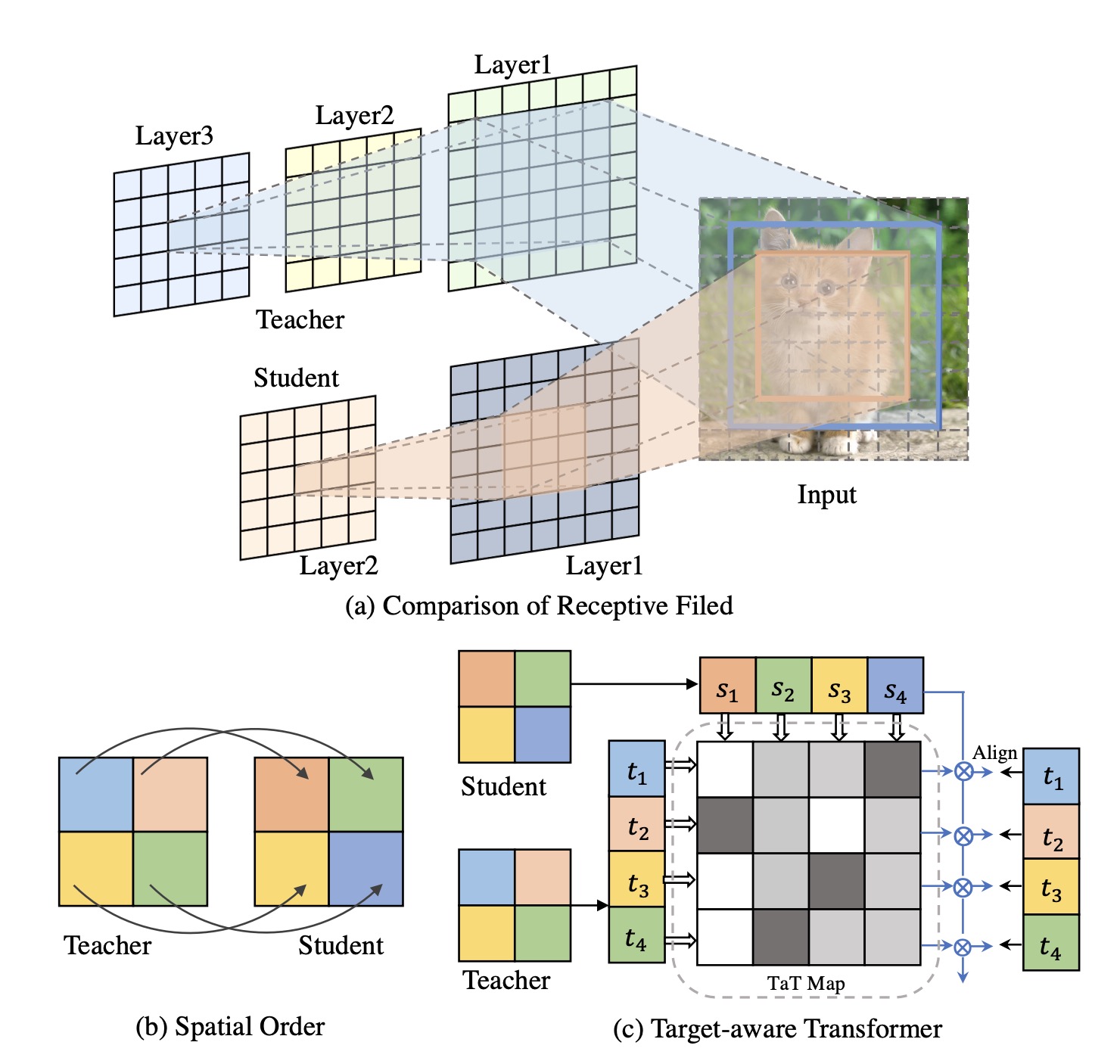
- propose a novel one-to-all spatial matching knowledge distillation approach
S. Lin, H. Xie, B. Wang, K, Yu, X. Chang, X. Liang, and G. Wang
CVPR 2022
pdf
An Efficient Spatio-Temporal Pyramid Transformer for Action Detection
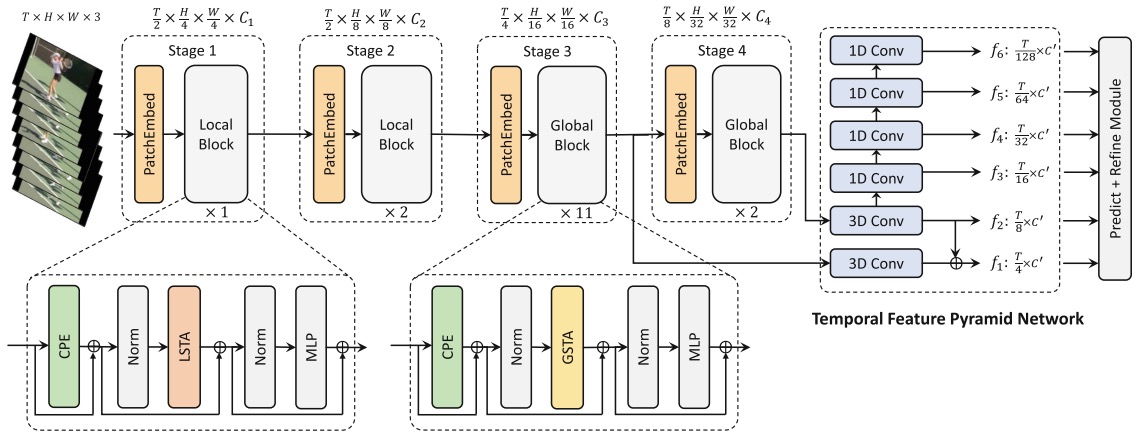
- propose an efficient and effective Spatio-Temporal Pyramid Transformer (STPT) for action detection, which reduces the huge computational cost and redundancy while capturing long-range dependency in spatio-temporal representation learning
Y. Weng, Z. Pan, M. Han, X. Chang and B. Zhuang
ECCV 2022
pdf
FFA-IR:Towards an Explainable and Reliable Medical Report Generation Benchmark

- present a new benchmark, FFA-IR, towards an explainable and reliable MRG benchmark based on FFA Images and Reports
M. Li, W. Cai, R. Liu, Y. Weng, X. Zhao, C. Wang, X. Chen, Z. Liu, C. Pan, M. Li, Y. Zheng, Y. Liu, F. D. Salim, K. Verspoor, X. Liang, X. Chang*
NeurIPS 2021
openreview
Exploring Inter-Channel Correlation for Diversity-preserved Knowledge Distillation
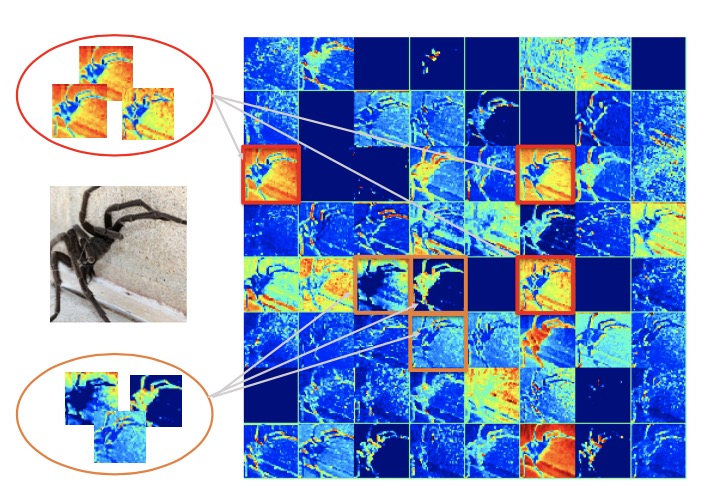
- introduce the inter-channel correlation, with the characteristics of being invariant to the spatial dimen- sion, to explore and measure both the feature diversity and homology to help the student for better represen- tation learning
L. Liu, Q. Huang, S. Lin, H. Xie, B. Wang, X. Chang* and X. Liang
ICCV 2021
arxiv
|
pdf
|
poster
Vision-Language Navigation with Random Environmental Mixup
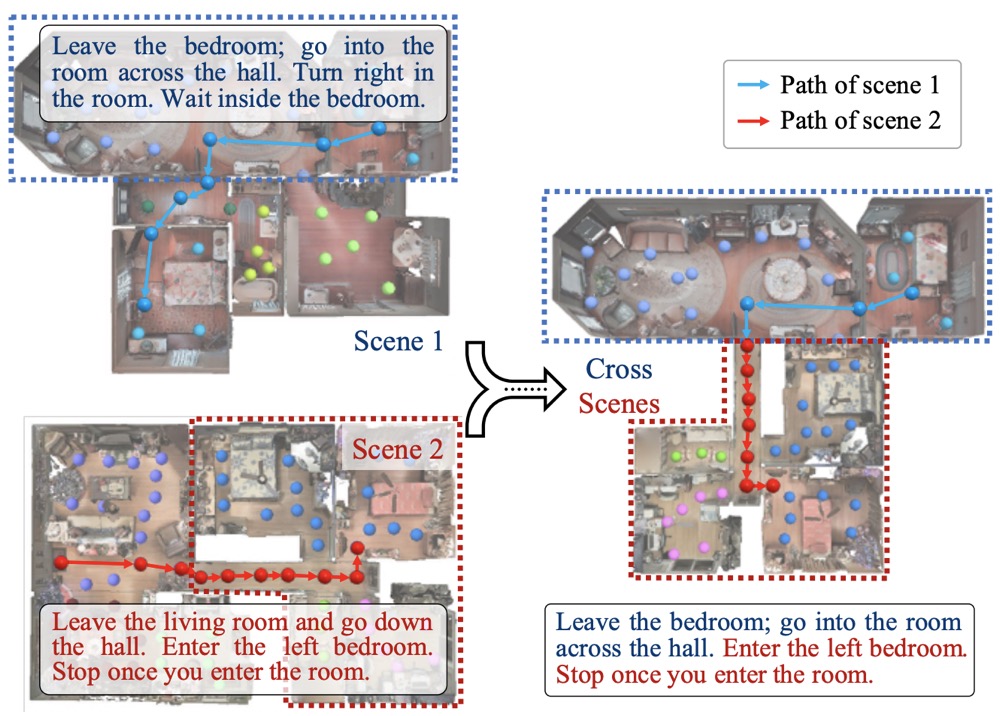
- propose the Random Environmen- tal Mixup (REM) method, which generates cross-connected house scenes as augmented data via mixuping environment
C. Liu, F. Zhu, X. Chang, X. Liang, Z. Ge and Y. Shen
ICCV 2021
arxiv
|
pdf
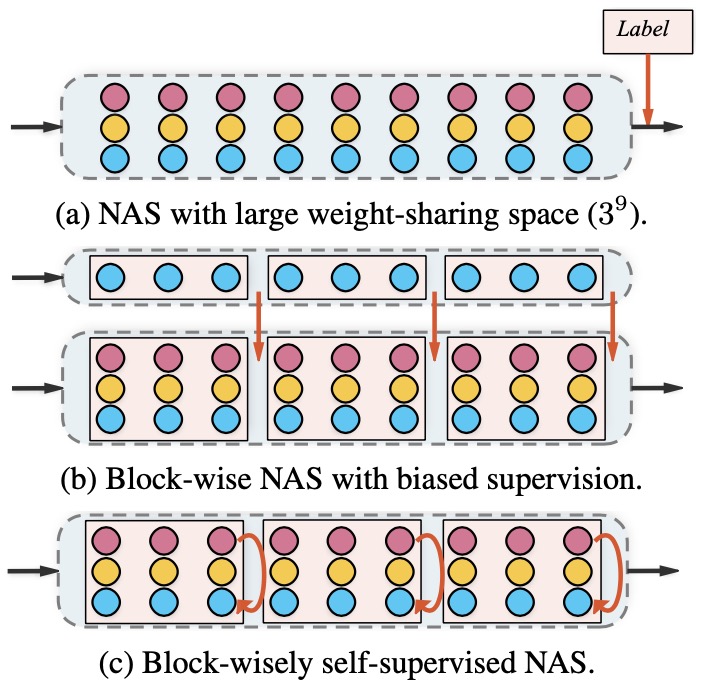
BossNAS:Exploring Hybrid CNN-transformers with Block-wisely Self-supervised Neural Architecture Search
- present Block-wisely Self-supervised Neural Architecture Search (BossNAS), an unsupervised NAS method that addresses the problem of in- accurate architecture rating caused by large weight-sharing space and biased supervision in previous methods
C. Li, T. Tang, G. Wang, J. Peng, B. Wang, X. Liang and X. Chang
ICCV 2021
arxiv
|
pdf
|
CODE
Dynamic Slimmable Network
- propose a new dynamic network routing regime, achieving good hardware-efficiency by predictively adjusting filter numbers of networks at test time with respect to different inputs.
C. Li, G. Wang, B. Wang, X. Liang, Z. Li, and X. Chang
CVPR 2021
paper
|
ORAL
|
CODE
SOON:Scenario Oriented Object Navigation with Graph-based Exploration
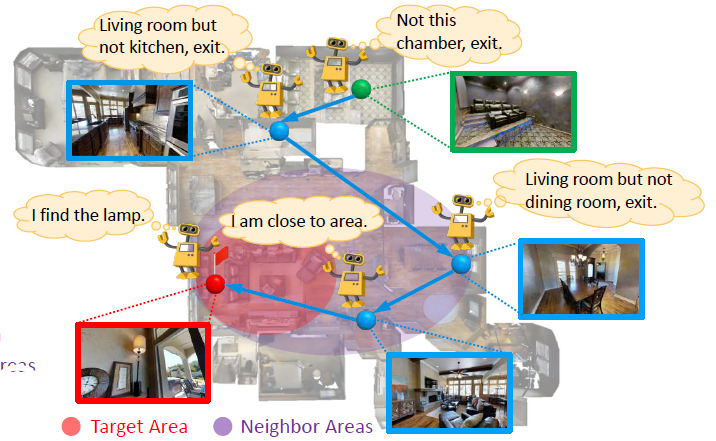
- propose a task named Scenario Oriented Object Navigation (SOON), in which an agent is instructed to find an object in a house from an arbitrary starting position
F. Zhu, X. Liang, Y. Zhu, X. Chang, Q. Yu, and X. Liang
CVPR 2021
paper
UPDeT:Universal Multi-agent RL via Policy Decoupling with Transformers
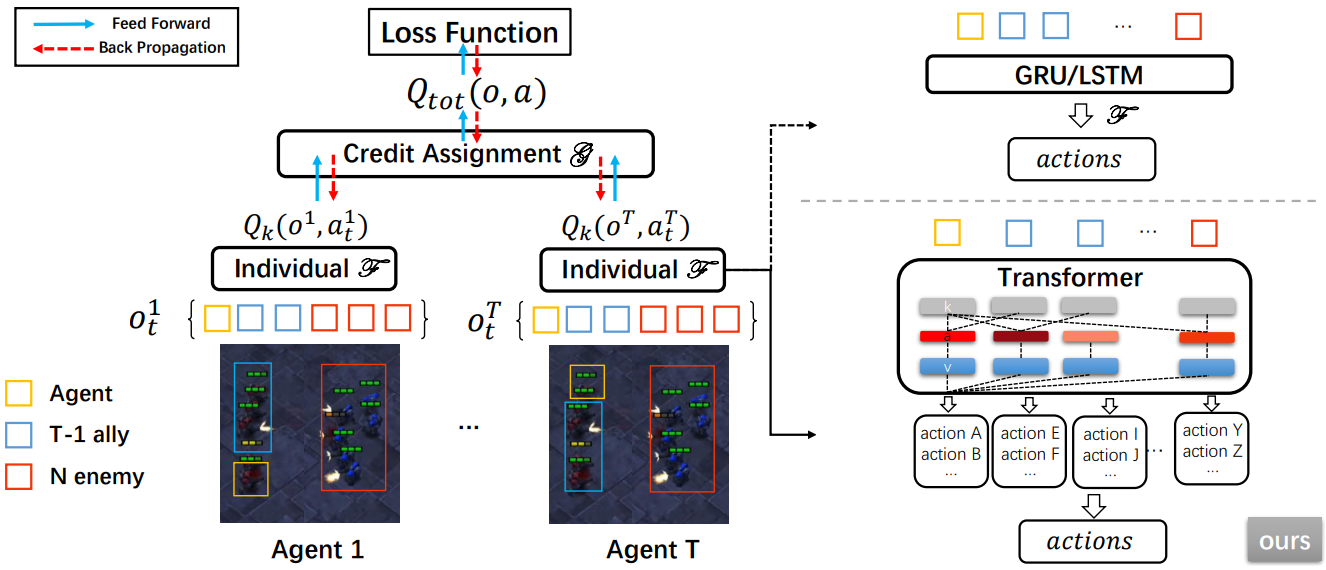
- propose a universal policy decoupling transformer model that extends MARL to a much broader scenario
S. Hu, F. Zhu, X. Chang and X. Liang
ICLR 2021
paper
iDARTS:Differentiable Architecture Search with Stochastic Implicit Gradients
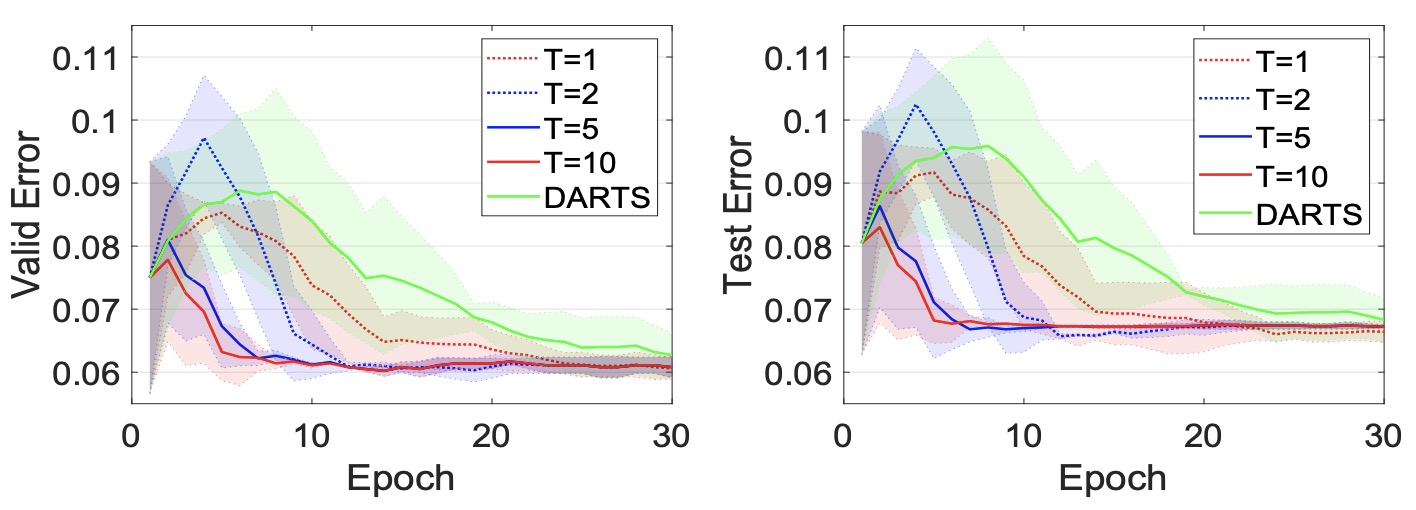
- This paper deepens our understanding of the hypergradient calculation in the differentiable NAS.
M. Zhang, S. Su, S. Pan, X. Chang, E. Abbasnejad and R. Haffari
ICML 2021
paper
Mining Inter-Video Proposal Relations for Video Object Detection
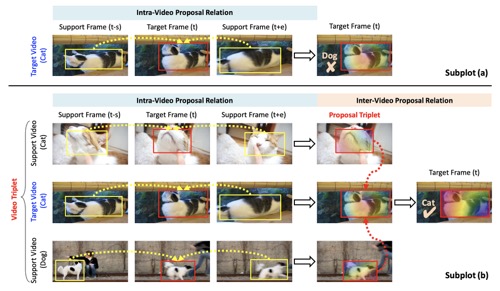
- design a novel Inter-Video Proposal Relation method, which can effectively leverage inter-video proposal relation to learn discriminative representations for video object detection
M. Han, Y. Wang, X. Chang and Y. Qiao
ECCV 2020
paper
|
code
Unsupervised Multimodal Neural Machine Translation with Pseudo Visual Pivoting
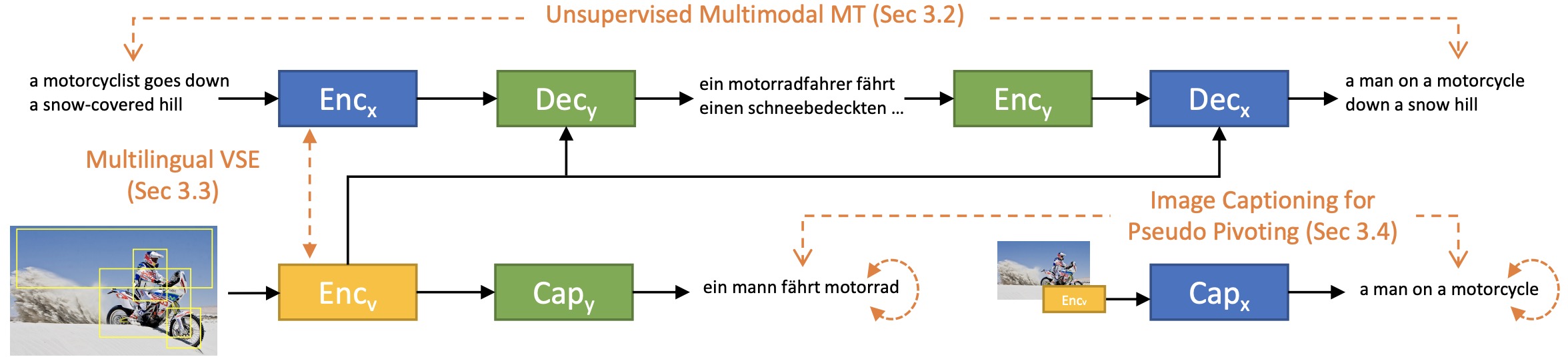
- investigate how to utilize visual content for disambiguation and latent space alignment in unsupervised MMT
P. Huang, J. Hu, X. Chang and A. Hauptmann
ACL 2020
paper
Vision-language Navigation with Self-Supervised Auxiliary Reasoning Tasks
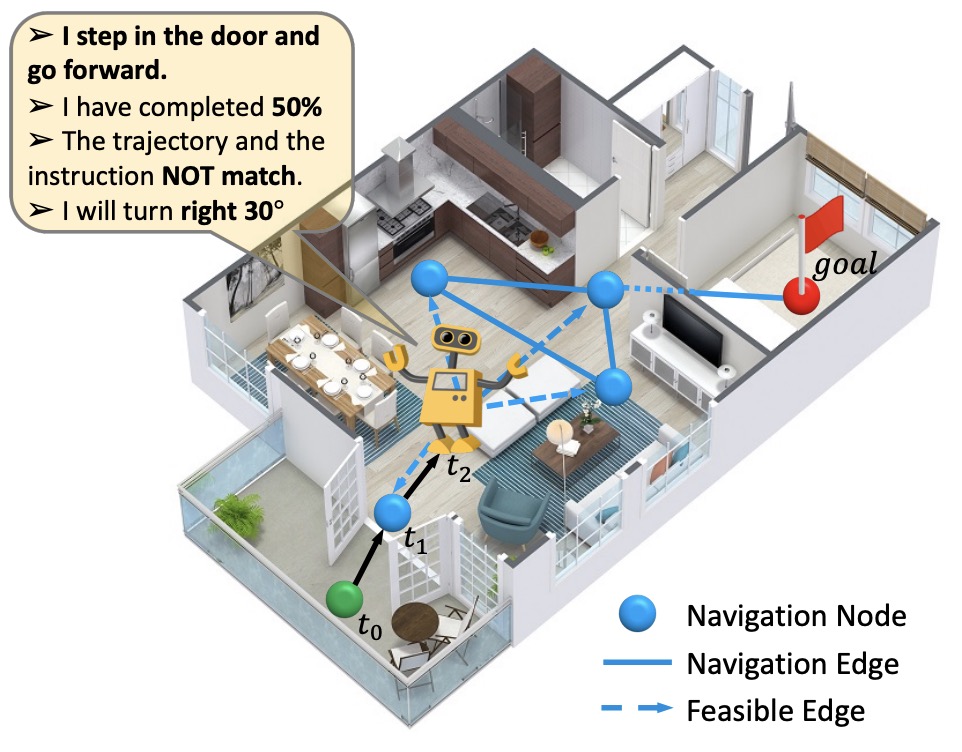
- Introducing Auxiliary Reasoning Navigation (AuxRN), a framework with four self-supervised auxiliary reasoning tasks to take advantage of the additional training signals derived from the semantic information
F. Zhu, Y. Zhu, X. Chang, X. Liang
CVPR 2020
paper
|
DEMO
|
CODE
|
Oral
ZSTAD:Zero-Shot Temporal Activity Detection
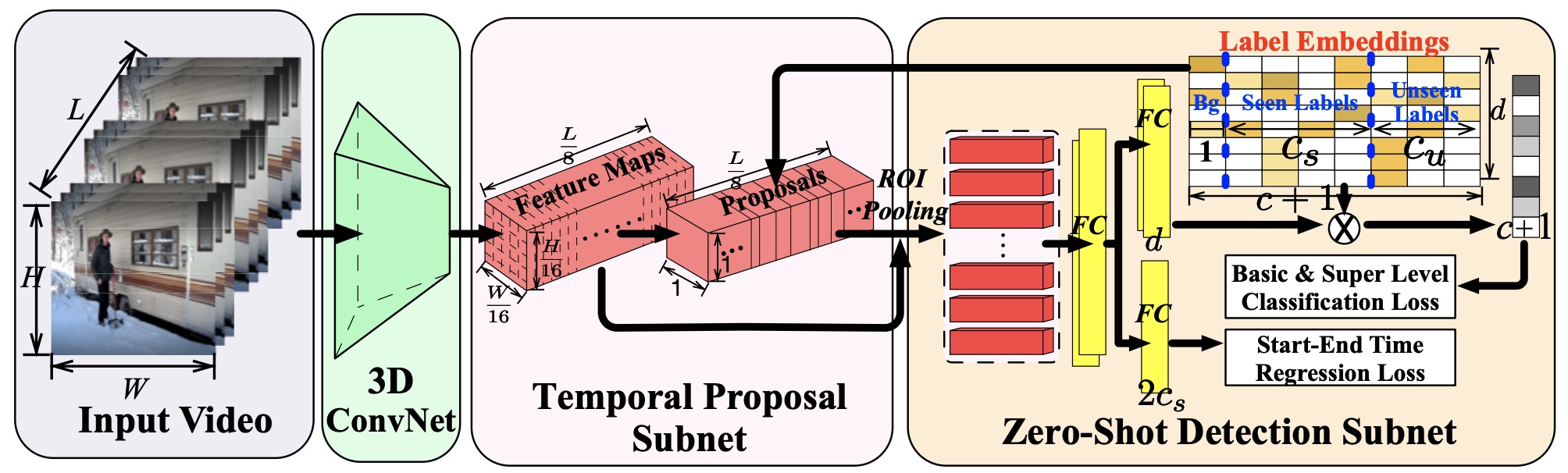
- Proposing a novel problem setting for temporal activity detection in which activities that are not seen during the training stage can be recognized and localized simultaneously
L. Zhang, X. Chang, J. Liu, S. Wang, Z. Ge, M. Luo, A. Hauptmann
CVPR 2020
paper
Unity Style Transfer for Person Re-Identification

- smooth the style disparities within the same camera and across different cameras
C. Liu, X. Chang, Y. Shen
CVPR 2020
paper
Neural Architecture Search by Block-wisely Distilling Architecture Knowledge
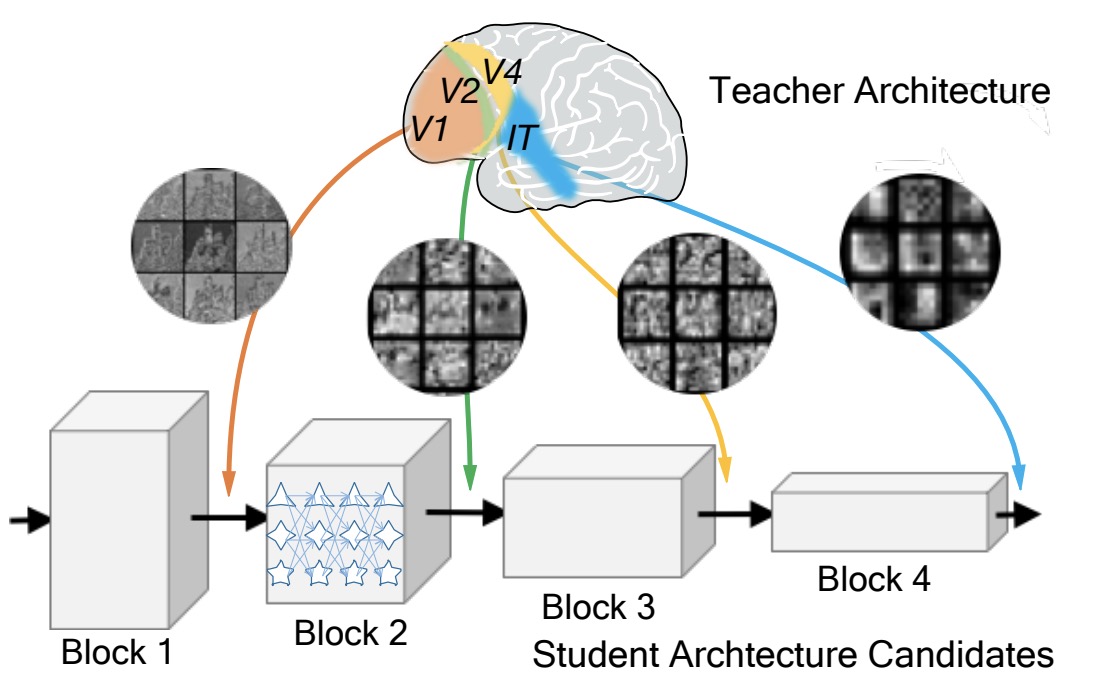
- modularize the large search space of NAS into blocks to ensure that the potential candidate architectures are fully trained
C. Li, J. Peng, L. Yuan, G. Wang, X. Liang, L. Lin, X. Chang
CVPR 2020
paper
|
code
Vision Dialogue Navigation by Exploring Cross-modal Memory
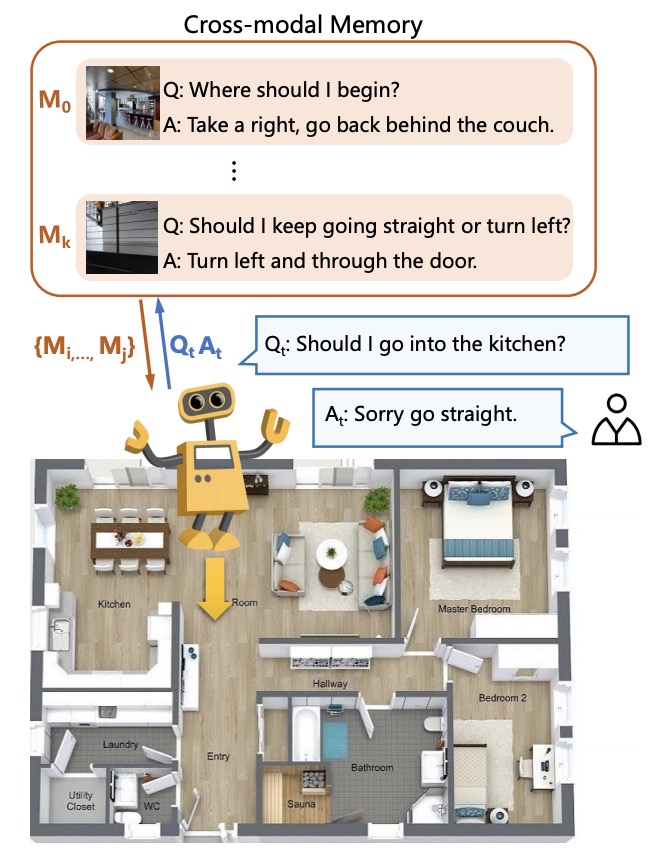
- learning an agent endowed with the capability of constant conversation for help with natural language and navigating according to human responses
- propose a Cross-modal Memory Network (CMN) for remembering and understanding the rich information relevant to historical navigation actions
Y. Zhu, F. Zhu, Z. Zhan, B. Lin, J. Jiao, X. Chang, X. Liang
CVPR 2020
paper
|
code
Overcoming Multi-Model Forgetting in One-Shot NAS with Diversity Maximization
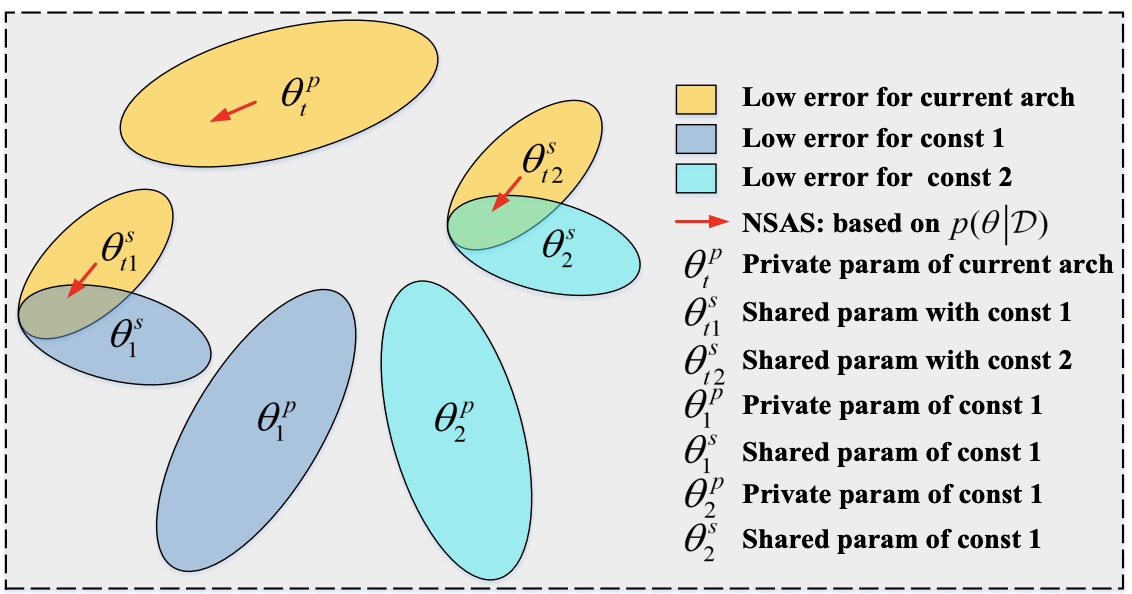
- formulate the supernet training in the One-Shot NAS as a constrained optimization problem of continual learning that the learning of current architecture should not degrade the performance of previous architectures during the supernet training
M. Zhang, H. Li, S. Pan, X. Chang, S. Su
CVPR 2020
paper
|
code
Differentiable Neural Architecture Search in Equivalent Space with Exploration Enhancement
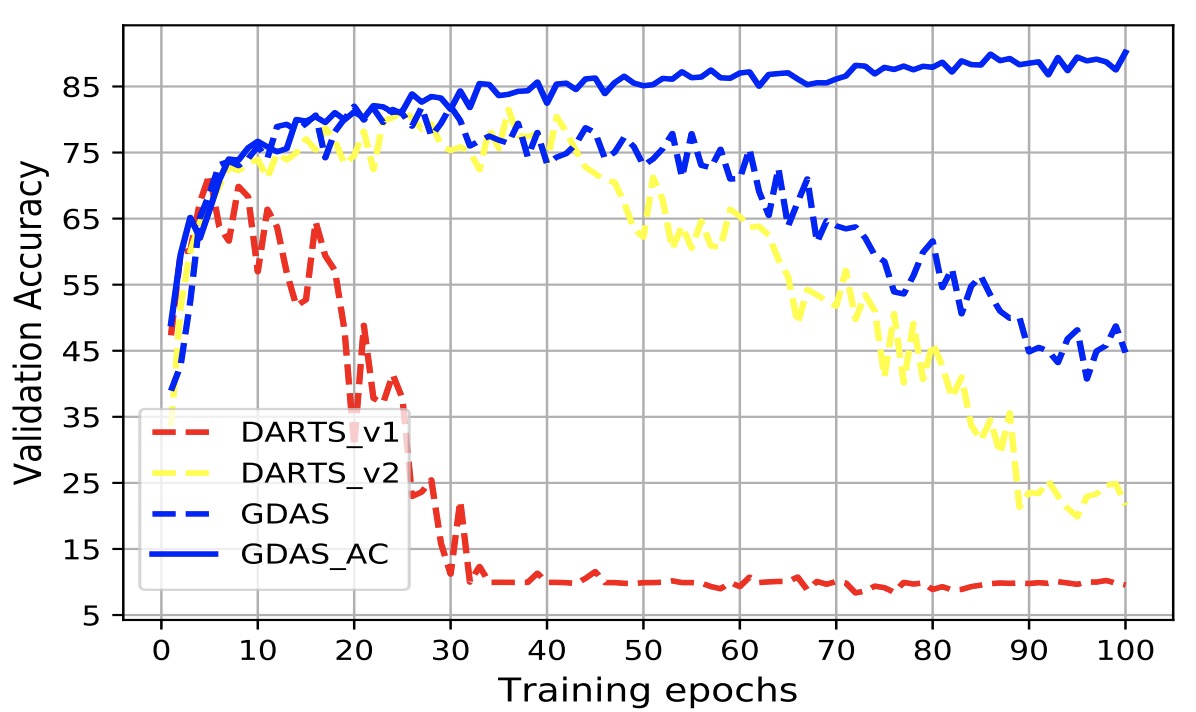
- enhance the intelligent exploration of differentiable Neural Architecture Search in the latent space
M. Zhang, H. Li, S. Pan, X. Chang, Z. Ge and S. Su
NeurIPS 2020
paper
|
code
Hierarchical Neural Architecture Search for Deep Stereo Matching
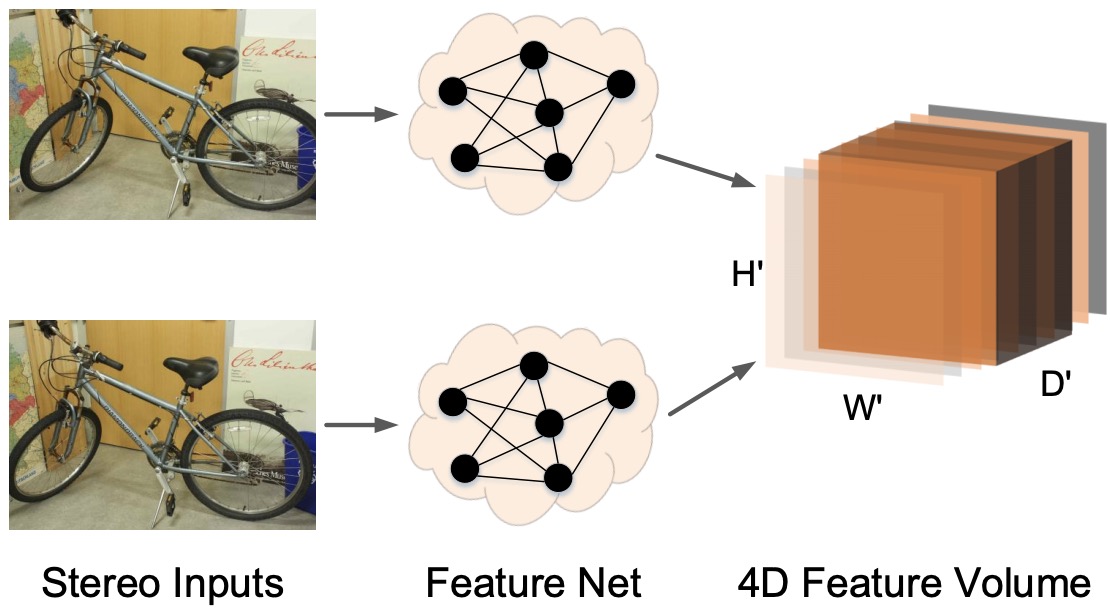
- leverage the volumetric stereo matching pipeline and allow the network to automat70 ically select the optimal structures for both the Feature Net and the Matching Net
X. Cheng, Y. Zhong, M. Harandi, Y. Dai, X. Chang, H. Li, T. Drummond, and Z. Ge
NeurIPS 2020
paper
|
code
Multi-Head Attention with Diversity for Learning Grounded Multilingual Multimodal Representations
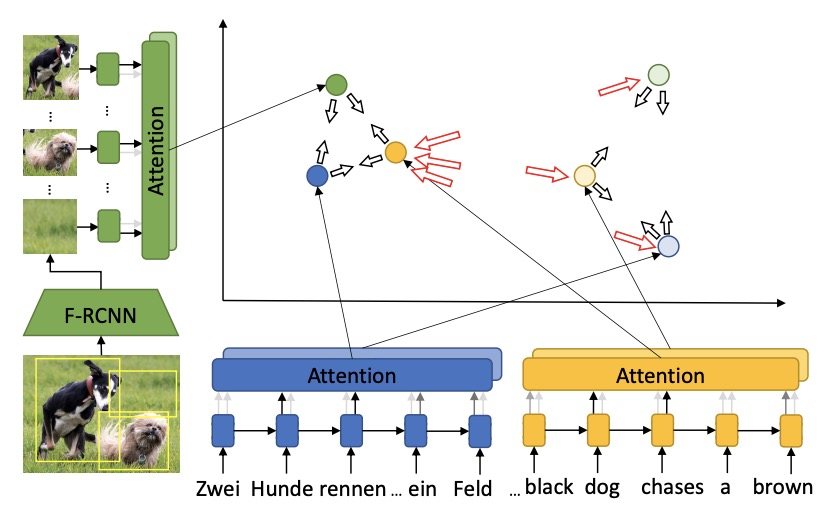
- leveraging visual object detection and propose a model with diverse multi-head attention to learn grounded multilingual multimodal representations
P. Huang, X. Chang, A. G. Hauptmann
EMNLP 2019
paper
Annotation Efficient Cross-Modal Retrieval with Adversarial Attentive Alignment
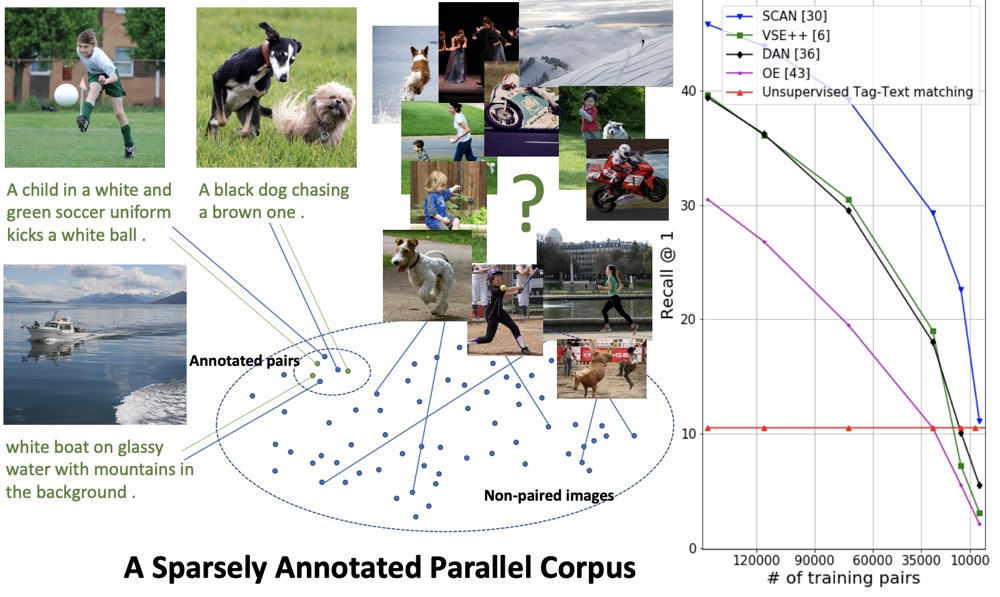
- propose a novel framework to leverage automatically extracted regional semantics from un-annotated images as additional weak supervision to learn visual-semantic embeddings
P. Huang, G. Kang, W. Liu, X. Chang, A. G. Hauptmann
ACM MM 2019
paper
RCAA:Relational Context-Aware Agents for Person Search
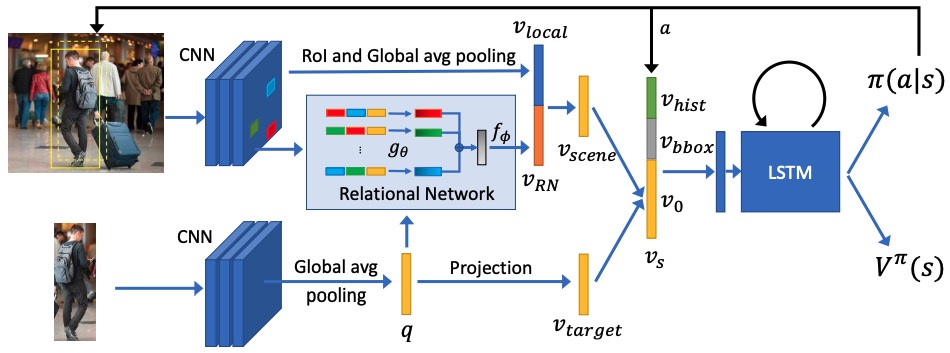
- made the earliest attempt to address the person search problem and built the first deep reinforcement learning based person search framework
X. Chang, P. Huang, Y. Shen, X. Liang, Y. Yang and A. G. Hauptmann
ECCV 2018
paper
Reinforcement Cutting-Agent Learning for Video Object Segmentation
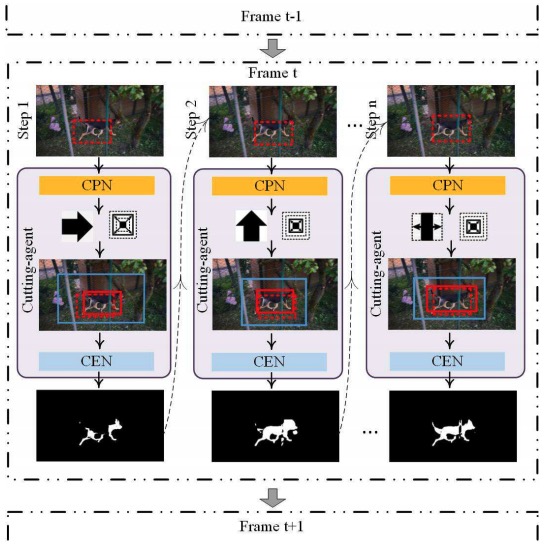
- make a pioneer effort to formulate the video object segmentation problem as a Markov Decision Process and propose a novel reinforcement cutting-agent learning framework to tackle this problem
J. Han, L. Yang, D. Zhang, X. Chang, X. Liang
CVPR 2018
paper
Complex Event Detection by Identifying Reliable Shots from Untrimmed Videos
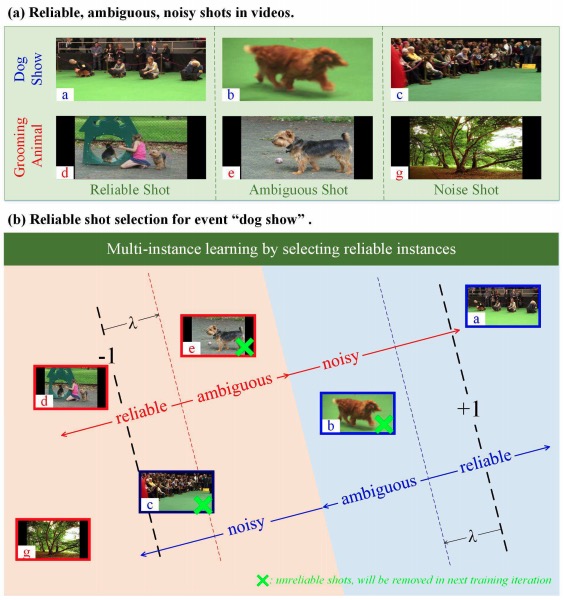
- simultaneously learns a linear SVM classifier and infers a binary indicator for each instance in order to select reliable training instances from each positive or negative bag
H. Fan, X. Chang, D. Cheng, Y. Yang, D. Xu, A. G. Hauptmann
ICCV 2017
paper
They are Not Equally Reliable:Semantic Event Search Using Differentiated Concept Classifiers

- combine the concept classifiers based on a principled estimate of their accuracy on the unlabeled test videos
X. Chang, Y. Yu, Y. Yang, E. P. Xing
CVPR 2016
paper
Complex Event Detection using Semantic Saliency and Nearly-Isotonic SVM
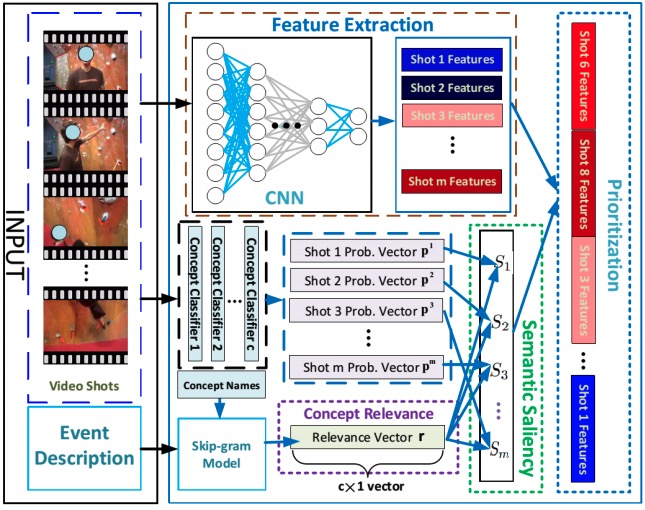
- define a novel notion of semantic saliency that assesses the relevance of each shot with the event of interest
X. Chang, Y. Yang, E. P. Xing, Y. Yu
ICML 2015
paper
|
code
Searching Persuasively:Joint Event Detection and Evidence Recounting with Limited Supervision
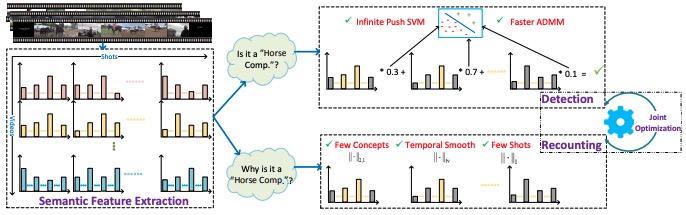
- propose a joint framework that simultaneously detects high-level events and localizes the indicative concepts of the events
X. Chang, Y. Yu, Y. Yang, A. G. Hauptmann
ACM MM 2015
paper
PREPRINTS
Vision Language Navigation with Multi-granularity Observation and Auxiliary Reasoning Tasks
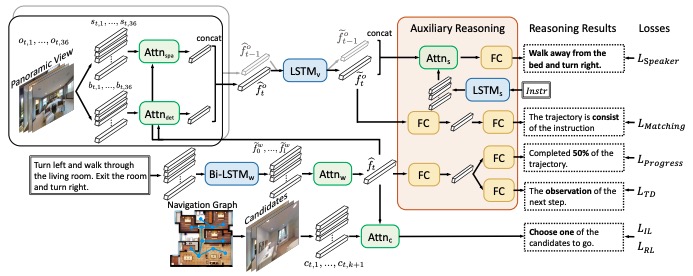
- we propose Multi-granularity Auxiliary Reason- ing Navigation (MG-AuxRN) to facilitate navigation learning. MG-AuxRN perceives multi-granularity input which combining dense object features and global image features.
Fengda Zhu, Yi Zhu, Yanxin Long, Xiaojun Chang, and Xiaodan Liang
Submitted to IEEE Trans. Pattern Anal. Mach. Intell. (T-PAMI), 2021
pdf
|
code